EgoCoT-Bench
Benchmarking Grounded and Verifiable Operation-Centric Chain-of-Thought Reasoning for MLLMs
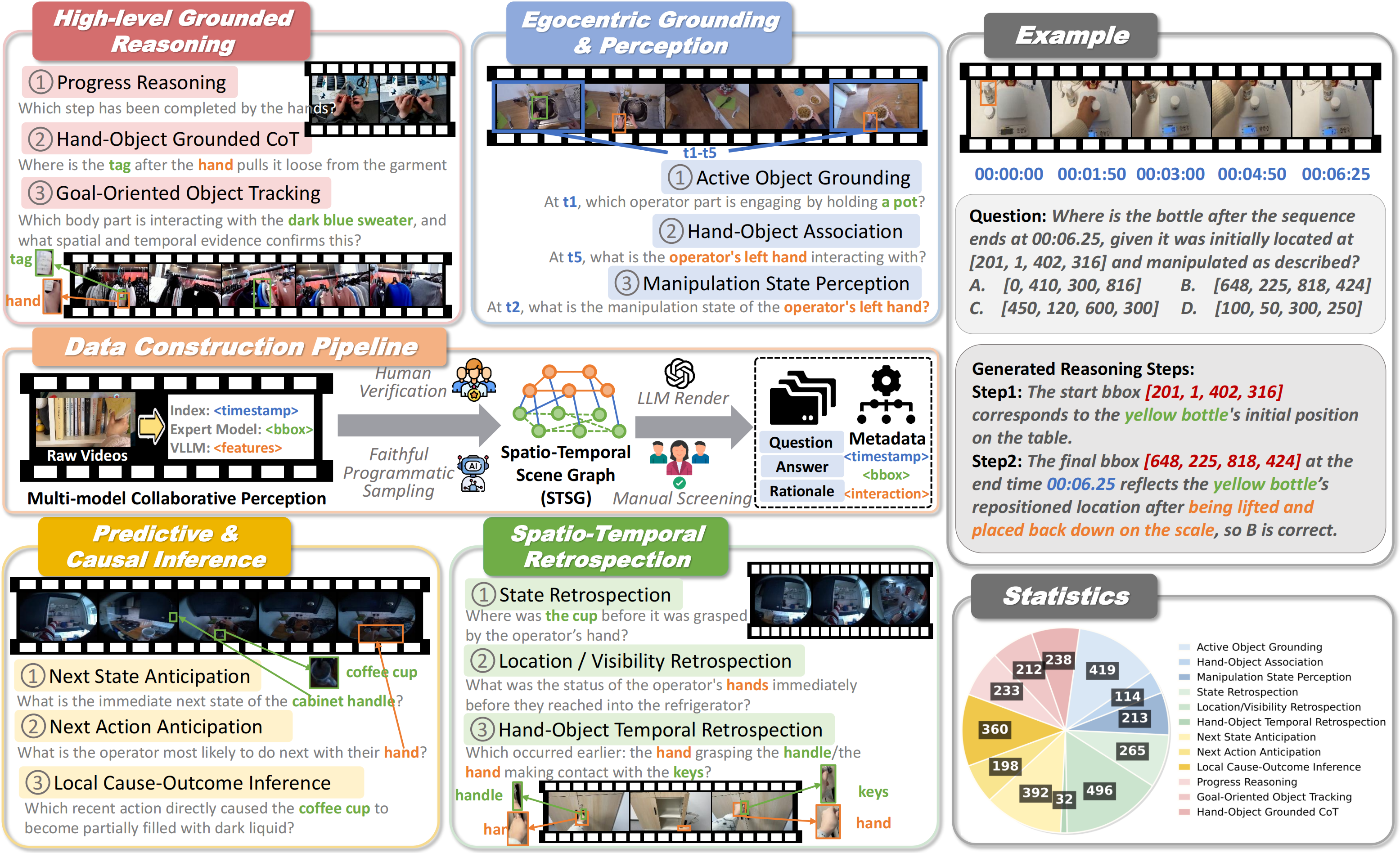
Abstract
The rapid development of multimodal large language models (MLLMs) has led to growing interest in egocentric video understanding, particularly in recognizing fine-grained hand-object interactions, tracking object state changes over time, and reasoning about manipulative processes in dynamic first-person environments. However, existing egocentric video benchmarks provide limited support for evaluating fine-grained operation-centric reasoning and rarely examine whether model rationales are grounded in explicit spatio-temporal evidence. To address this gap, we introduce EgoCoT-Bench, a fine-grained egocentric benchmark for grounded and verifiable operation-centric reasoning with explicit step-by-step rationale annotations. EgoCoT-Bench comprises 3,172 verifiable QA pairs over 351 egocentric videos, organized into 4 task groups and 12 subtasks spanning perception, retrospection, anticipation, and high-level reasoning. The benchmark is constructed through an STSG-guided generation framework and further refined by human annotators to ensure correctness, egocentric relevance, and fine-grained annotation quality. Experimental results show that egocentric fine-grained reasoning remains highly challenging, and further reveal that many multimodal models produce correct answers with inconsistent supporting evidence.
Dataset at a Glance
- 351 egocentric videos
- 3,172 verifiable QA pairs
- 4 task groups
- 12 fine-grained subtasks
- Annotations: QA labels, step-by-step rationales, task labels, and released evidence metadata (timestamps, bounding boxes, interaction relations, and focused anchors where available)
- Metrics: Accuracy, Reasoning Score (R), and Spurious Correct Rate (SCR)
Task Definition
EgoCoT-Bench structures questions into four operation-centric task groups: Egocentric Grounding and Perception, Spatio-Temporal Retrospection , Predictive and Causal Inference, and High-level Grounded Reasoning, covering fine-grained grounding, retrospection, anticipation, and high-level reasoning.
Annotation Schema
Each accepted sample is constructed with a question-answer pair, step-by-step reasoning, and structured spatio-temporal evidence. For public presentation, we expose the core annotation fields and released evidence metadata where available, while omitting reviewer-side copies, reconciliation records, and private test labels.
- Sample identity:
qid,media_id,source - Task taxonomy:
big_category_en,sub_category_en - QA annotation:
question,choices,answer - Reasoning annotation:
reasoningwith step-by-step rationale - Evidence annotation: target objects, timestamps, bounding boxes, interaction relations, and focused evidence anchors
Internal review fields such as reviewer copies, review status, and reconciliation metadata are omitted here for clarity.
{
"qid": "ego_000000",
"media_id": "P01_01_7_scaled_910x512_4fps_887175d5",
"source": "media/P01_01_7_scaled_910x512_4fps_887175d5.mp4",
"big_category_en": "Egocentric Grounding & Perception",
"sub_category_en": "Active Object Grounding",
"question": "At 1.0 seconds, which operator body part is actively engaging the scene by holding a black pot near the sink with running water?",
"choices": {
"A": "right hand",
"B": "left hand",
"C": "chin",
"D": "forehead"
},
"answer": "B",
"reasoning": {
"step1": "At 00:01.00, the target appears in the lower-left region with bbox evidence consistent with left-hand placement in egocentric view.",
"step2": "The structured evidence and natural-language description jointly indicate that the left hand is holding the pot at this moment."
},
"evidence": {
"target_objects": [
{
"distinct_id": 3,
"label": "left hand"
}
],
"timestamps": [
"00:01.00",
"00:02.00",
"00:03.00"
],
"bboxes": [
{
"distinct_id": 3,
"time": "00:01.00",
"bbox": [329, 317, 470, 511]
}
],
"relations": [
{
"subject_name": "left hand",
"predicate": "near",
"object_name": "bottle",
"time": ["00:01.00", "00:01.00"]
},
{
"subject_name": "camera wearer (operator)",
"predicate": "manipulates objects using",
"object_name": "left hand",
"time": ["00:01.00"]
}
],
"focus_times": ["00:01.00"],
"focused_bboxes": [
{
"distinct_id": 3,
"time": "00:01.00",
"bbox": [329, 317, 470, 511]
}
]
}
}Licensing & Access
EgoCoT-Bench uses a layered licensing model. The benchmark annotations and metadata are released by EgoCoT-Bench for research and non-commercial use, while third-party video sources remain governed by their original licenses, access agreements, and redistribution policies.
Dataset Availability
The benchmark annotations and metadata are hosted on Hugging Face . The public release is organized for benchmark evaluation, qualitative inspection, and reproducible comparison. Public development examples may include answers, rationales, and released evidence metadata; public test examples omit official answers and private rationales to avoid label leakage.
Public Access Scope
- Public development split: released for browsing, inspection, method development, and qualitative analysis. Public development examples may include answers, rationales, task labels, and released evidence metadata.
- Public test split: released for benchmarking and submission preparation. Official test answers and private rationale annotations are not publicly released.
- Media files: media files referenced by EgoCoT-Bench may include self-recorded media and/or media derived from third-party egocentric video datasets. Third-party media remains subject to the original source dataset licenses and terms.
Layered License
The Hugging Face dataset license metadata (CC BY-NC 4.0) refers to the EgoCoT-Bench annotations, benchmark metadata, and self-recorded media where provided. It does not override the licenses or access terms of third-party video datasets.
| Component | License / Terms | Scope |
|---|---|---|
| Annotations and benchmark metadata | CC BY-NC 4.0 | Questions, answer choices, task labels, public rationales, temporal anchors, bounding boxes, interaction relations, and other released evidence metadata. |
| Self-recorded media, where provided | CC BY-NC 4.0 | Released for research and non-commercial use, subject to consent and privacy constraints. |
| Evaluation code and leaderboard utilities | Apache License 2.0 | Applies only to code files, unless a file explicitly states otherwise. |
| Third-party videos or derived clips | Original source dataset terms | EgoCoT-Bench does not re-license third-party videos. Users must follow the corresponding source dataset licenses, access agreements, and redistribution policies. |
Third-Party Source Terms
EgoCoT-Bench builds on multiple egocentric video sources, including Ego4D, EPIC-KITCHENS, Charades-Ego, MECCANO, and HD-EPIC. The EgoCoT-Bench annotations are released by the authors, while the underlying source videos remain governed by the original providers.
- Users should obtain and use third-party media according to the official access rules and license terms of each source dataset.
- Users should not redistribute third-party raw videos or derived clips unless redistribution is explicitly permitted by the original source license.
- Users should cite both EgoCoT-Bench and the relevant original video datasets when using samples derived from those sources.
Responsible Use
- EgoCoT-Bench is intended for research and non-commercial use in multimodal reasoning, egocentric video understanding, grounded QA, and evidence-aware evaluation.
- Users should not use EgoCoT-Bench to identify private individuals or infer sensitive personal attributes from video content.
- Users should not interpret benchmark performance as a real-world safety guarantee without additional validation.
- If you build upon EgoCoT-Bench, please cite the paper, link to the official dataset repository, and cite the relevant source video datasets.
Citation and Contact
If you use EgoCoT-Bench in your research, please cite the accompanying paper. For questions regarding access, annotation format, licensing, or benchmark usage, please contact the authors via the email addresses listed on this project page.
Overall Statistics
Overall statistics of EgoCoT-Bench, including an overview of benchmark dimensions and the distribution of video sources.
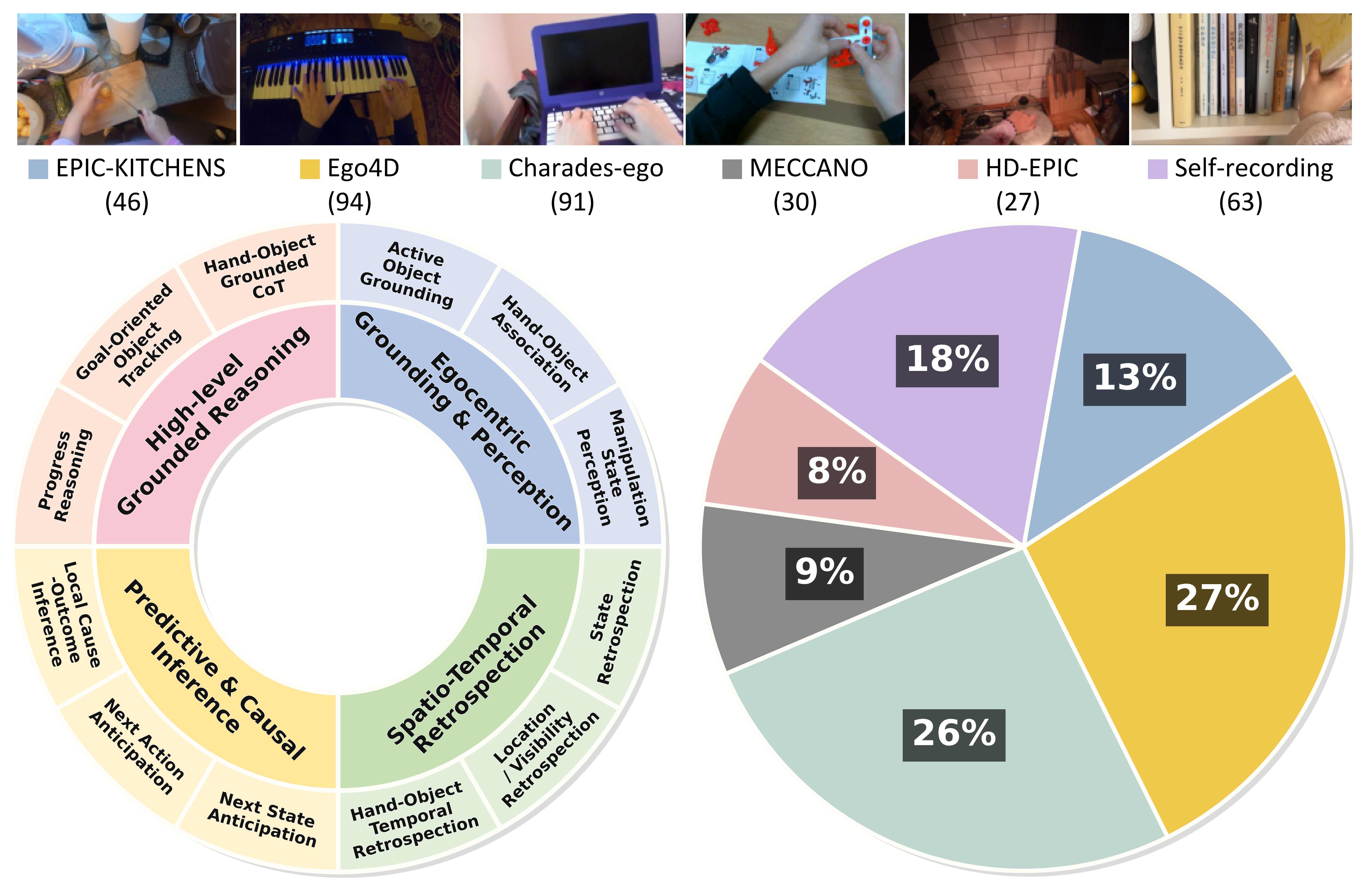
Figure 2. Overall statistics of EgoCoT-Bench.
EgoCoT-Bench Leaderboard
Results are reported using both accuracy (%) and reasoning-oriented metrics. The first table is ranked globally by Mean Accuracy. The second table reports Reasoning Score (R) and Spurious Correct Rate (SCR), and can be sorted by Mean R or Mean SCR. Human is shown only as an accuracy reference row.
Orange Proprietary model Blue Open-source model Green Human reference
Accuracy Leaderboard
| # | Method | Mean |
EGP
Egocentric Grounding & Perception |
STR
Spatio-Temporal Retrospection |
PCI
Predictive & Causal Inference |
HGR
High-level Grounded Reasoning |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AOG | HOA | MSP | Mean | SR | LVR | HOTR | Mean | NSA | NAA | LCOI | Mean | PR | HGC | GOT | Mean | |||
| – | Human | 95.93 | 96.18 | 93.86 | 97.18 | 96.11 | 93.96 | 95.36 | 96.88 | 94.96 | 98.47 | 94.44 | 95.00 | 96.32 | 98.71 | 97.90 | 91.98 | 96.34 |
| 1 🥇 | Qwen3.5-27B | 71.28 | 68.26 | 61.40 | 84.51 | 71.85 | 72.83 | 67.74 | 59.38 | 69.10 | 84.65 | 68.69 | 73.33 | 77.03 | 77.68 | 80.67 | 34.43 | 65.30 |
| 2 🥈 | Qwen3.5-Plus | 70.68 | 68.26 | 62.28 | 85.92 | 72.39 | 67.55 | 60.69 | 53.12 | 62.67 | 85.20 | 70.71 | 74.72 | 78.21 | 81.12 | 82.77 | 35.85 | 67.64 |
| 3 🥉 | Qwen3.5-397B-A17B | 70.11 | 68.26 | 58.77 | 87.79 | 72.39 | 69.81 | 59.07 | 56.25 | 62.55 | 84.95 | 68.18 | 70.83 | 76.11 | 78.97 | 83.61 | 38.68 | 68.08 |
| 4 | Qwen3.5-122B-A10B | 69.96 | 68.26 | 61.40 | 86.38 | 72.39 | 70.72 | 62.70 | 56.25 | 65.11 | 81.63 | 70.71 | 73.61 | 76.32 | 79.83 | 79.41 | 30.19 | 64.28 |
| 5 | GPT-5.2 | 67.91 | 64.92 | 62.28 | 72.30 | 66.62 | 67.55 | 59.88 | 59.38 | 62.42 | 84.69 | 64.14 | 72.22 | 75.68 | 65.24 | 84.03 | 42.92 | 64.86 |
| 6 | Qwen3-VL-Plus | 67.12 | 69.21 | 61.40 | 77.00 | 70.24 | 69.70 | 54.66 | 56.25 | 59.75 | 84.69 | 66.16 | 71.94 | 76.00 | 68.53 | 77.54 | 32.70 | 60.53 |
| 7 | Qwen3-VL-32B | 67.09 | 67.78 | 62.28 | 79.81 | 70.38 | 64.53 | 55.04 | 68.75 | 58.76 | 84.18 | 70.20 | 71.67 | 76.53 | 69.10 | 79.83 | 27.83 | 60.03 |
| 8 | GPT-5.1 | 66.71 | 64.20 | 63.16 | 77.00 | 67.69 | 66.04 | 49.40 | 56.25 | 55.23 | 86.99 | 67.17 | 70.56 | 76.63 | 68.24 | 79.83 | 45.28 | 65.15 |
| 9 | Qwen3-VL-235B-A22B | 65.86 | 67.54 | 57.02 | 77.00 | 68.63 | 71.32 | 52.82 | 56.25 | 59.14 | 85.97 | 68.18 | 62.50 | 73.37 | 70.82 | 78.99 | 27.36 | 60.18 |
| 10 | Qwen3-VL-8B | 65.42 | 69.54 | 59.29 | 81.60 | 71.43 | 64.02 | 60.69 | 59.38 | 61.75 | 83.03 | 63.13 | 64.72 | 71.91 | 59.91 | 78.15 | 25.00 | 55.43 |
| 11 | Qwen3-VL-30B-A3B | 64.63 | 62.44 | 61.06 | 82.16 | 67.88 | 65.15 | 65.86 | 62.50 | 65.49 | 81.89 | 59.09 | 66.94 | 71.47 | 66.52 | 73.11 | 9.05 | 51.10 |
| 12 | InternVL3.5-14B | 64.09 | 56.32 | 56.14 | 75.12 | 61.66 | 56.98 | 63.71 | 75.00 | 61.92 | 78.32 | 65.66 | 70.00 | 72.53 | 61.37 | 72.27 | 36.79 | 57.54 |
| 13 | InternVL3.5-8B | 64.06 | 56.32 | 61.40 | 70.89 | 61.26 | 54.34 | 67.74 | 68.75 | 63.30 | 80.36 | 66.16 | 67.22 | 72.42 | 66.95 | 73.11 | 25.94 | 56.37 |
| 14 | InternVL3.5-4B | 61.95 | 58.71 | 59.65 | 73.24 | 63.00 | 48.30 | 54.44 | 62.50 | 52.71 | 81.63 | 59.60 | 63.06 | 70.00 | 64.81 | 75.63 | 38.21 | 60.32 |
| 15 | InternVL3.5-2B | 61.79 | 50.60 | 63.16 | 79.81 | 60.86 | 58.11 | 66.94 | 71.88 | 64.18 | 77.30 | 59.09 | 58.33 | 66.32 | 60.94 | 71.01 | 26.42 | 53.73 |
| 16 | LLaVA-OneVision-1.5-8B | 60.81 | 53.94 | 58.77 | 74.65 | 60.59 | 57.36 | 51.61 | 40.62 | 53.09 | 82.14 | 69.19 | 61.94 | 71.79 | 68.67 | 71.01 | 21.23 | 54.76 |
| 17 | LLaVA-OneVision-1.5-4B | 60.78 | 55.74 | 54.39 | 72.30 | 60.27 | 61.51 | 55.04 | 40.62 | 56.62 | 81.38 | 61.11 | 61.67 | 69.68 | 63.95 | 73.11 | 21.23 | 53.88 |
| 18 | InternVL3.5-1B | 53.91 | 41.77 | 55.26 | 69.95 | 51.88 | 44.91 | 51.21 | 75.00 | 50.06 | 64.29 | 55.56 | 56.94 | 59.68 | 55.36 | 67.65 | 32.55 | 52.56 |
| 19 | LLaVA-NeXT-Video-7B | 44.26 | 35.08 | 55.26 | 46.95 | 41.55 | 46.42 | 40.93 | 56.25 | 43.38 | 62.24 | 48.99 | 48.61 | 54.32 | 33.91 | 49.58 | 17.45 | 34.26 |
The accuracy table is globally sorted by Mean, while model type is indicated by method-name color.
Reasoning Leaderboard
| # | Method | Type | Mean Mean |
EGP
Egocentric Grounding & Perception |
STR
Spatio-Temporal Retrospection |
PCI
Predictive & Causal Inference |
HGR
High-level Grounded Reasoning |
|||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R ↑ | SCR ↓ | R ↑ | SCR ↓ | R ↑ | SCR ↓ | R ↑ | SCR ↓ | R ↑ | SCR ↓ | |||
| GPT-5.1 | Proprietary | 2.77 | 4.91 | 2.65 | 5.35 | 2.16 | 5.25 | 3.43 | 1.79 | 2.67 | 9.21 | |
| GPT-5.2 | Proprietary | 2.85 | 4.27 | 2.39 | 3.23 | 2.73 | 4.02 | 3.40 | 2.36 | 2.76 | 8.80 | |
| Qwen3-VL-Plus | Proprietary | 3.08 | 7.84 | 3.04 | 7.44 | 2.61 | 5.29 | 3.64 | 6.37 | 2.87 | 13.87 | |
| Qwen3.5-Plus | Proprietary | 2.92 | 9.10 | 2.88 | 7.41 | 2.31 | 10.87 | 3.50 | 7.67 | 2.87 | 11.47 | |
| InternVL3.5-1B | Open-source | 2.21 | 13.33 | 2.11 | 8.53 | 1.77 | 17.63 | 2.70 | 8.99 | 2.14 | 20.61 | |
| InternVL3.5-2B | Open-source | 2.53 | 7.86 | 2.43 | 9.69 | 2.29 | 7.86 | 2.98 | 2.70 | 2.29 | 14.44 | |
| InternVL3.5-4B | Open-source | 2.45 | 9.57 | 2.39 | 8.72 | 1.86 | 9.57 | 3.09 | 4.96 | 2.31 | 17.96 | |
| LLaVA-OneVision-1.5-4B | Open-source | 2.50 | 9.57 | 2.32 | 10.47 | 2.03 | 14.92 | 3.17 | 3.77 | 2.32 | 13.59 | |
| LLaVA-NeXT-Video-7B | Open-source | 1.85 | 22.93 | 1.57 | 25.16 | 1.51 | 35.46 | 2.59 | 8.53 | 1.53 | 33.33 | |
| InternVL3.5-8B | Open-source | 2.56 | 5.61 | 2.39 | 5.47 | 2.25 | 4.98 | 3.15 | 3.92 | 2.30 | 9.61 | |
| LLaVA-OneVision-1.5-8B | Open-source | 2.21 | 24.73 | 2.08 | 28.31 | 1.76 | 27.31 | 2.77 | 21.11 | 2.08 | 24.06 | |
| Qwen3-VL-8B | Open-source | 2.73 | 10.07 | 2.74 | 9.25 | 2.29 | 14.40 | 3.27 | 6.46 | 2.47 | 12.17 | |
| InternVL3.5-14B | Open-source | 2.60 | 5.36 | 2.50 | 5.43 | 2.27 | 4.48 | 3.17 | 2.46 | 2.30 | 11.45 | |
| Qwen3.5-27B | Open-source | 2.96 | 7.25 | 2.87 | 8.39 | 2.49 | 8.94 | 3.56 | 3.15 | 2.78 | 10.54 | |
| Qwen3-VL-30B-A3B | Open-source | 2.79 | 7.25 | 2.73 | 8.91 | 2.43 | 10.42 | 3.36 | 5.89 | 2.46 | 7.76 | |
| Qwen3-VL-32B | Open-source | 2.96 | 7.99 | 2.88 | 9.90 | 2.40 | 7.51 | 3.63 | 5.36 | 2.77 | 10.73 | |
| Qwen3.5-122B-A10B | Open-source | 2.94 | 9.73 | 2.83 | 11.29 | 2.43 | 11.26 | 3.48 | 7.45 | 2.88 | 9.79 | |
| Qwen3-VL-235B-A22B | Open-source | 2.78 | 11.01 | 2.70 | 11.32 | 2.32 | 9.38 | 3.42 | 8.90 | 2.53 | 16.05 | |
| Qwen3.5-397B-A17B | Open-source | 2.87 | 10.93 | 2.86 | 9.81 | 2.29 | 12.70 | 3.37 | 9.82 | 2.87 | 12.04 | |
R is reported on a strict 0–5 scale and SCR in percentage (%). Higher R is better, while lower SCR indicates better answer-reasoning consistency.
Source-wise Analysis
To examine whether the self-recorded subset behaves differently from public-source samples, we conduct a source-wise analysis with five representative MLLMs: InternVL3.5-1B, InternVL3.5-2B, InternVL3.5-8B, LLaVA-OneVision-1.5-4B, and Qwen3-VL-Plus. For each model, we aggregate results across all four task groups and compare different video sources using Accuracy, Reasoning Score (R), and Spurious Correct Rate (SCR).
As one representative example, for InternVL3.5-8B, public-source samples obtain Acc/R/SCR = 64.08/2.54/4.64 over 2,859 samples, while self-recorded samples obtain Acc/R/SCR = 59.75/2.36/4.28 over 313 samples. These results suggest that the self-recorded subset is not an artificially easier source and shows comparable answer-reasoning consistency to public-source samples.
Results by Video Source
| Model | Video Source | #Samples | Acc (%) | R | SCR (%) |
|---|---|---|---|---|---|
| InternVL3.5-1B | Charades-Ego | 628 | 53.66 | 2.17 | 14.54 |
| InternVL3.5-1B | EPIC-KITCHENS | 266 | 57.14 | 2.13 | 16.45 |
| InternVL3.5-1B | Ego4D | 1,351 | 55.59 | 2.30 | 11.98 |
| InternVL3.5-1B | HD-EPIC | 463 | 52.70 | 2.18 | 12.70 |
| InternVL3.5-1B | MECCANO | 151 | 51.66 | 2.13 | 15.38 |
| InternVL3.5-1B | Self-recording | 313 | 50.48 | 2.08 | 12.03 |
| InternVL3.5-2B | Charades-Ego | 628 | 58.76 | 2.38 | 7.86 |
| InternVL3.5-2B | EPIC-KITCHENS | 266 | 59.77 | 2.55 | 6.29 |
| InternVL3.5-2B | Ego4D | 1,351 | 60.77 | 2.52 | 6.21 |
| InternVL3.5-2B | HD-EPIC | 463 | 62.20 | 2.53 | 6.25 |
| InternVL3.5-2B | MECCANO | 151 | 64.90 | 2.58 | 6.12 |
| InternVL3.5-2B | Self-recording | 313 | 62.94 | 2.51 | 6.09 |
| InternVL3.5-8B | Charades-Ego | 628 | 64.97 | 2.52 | 4.17 |
| InternVL3.5-8B | EPIC-KITCHENS | 266 | 62.78 | 2.47 | 5.39 |
| InternVL3.5-8B | Ego4D | 1,351 | 64.99 | 2.59 | 5.13 |
| InternVL3.5-8B | HD-EPIC | 463 | 60.91 | 2.46 | 3.19 |
| InternVL3.5-8B | MECCANO | 151 | 64.24 | 2.65 | 5.15 |
| InternVL3.5-8B | Self-recording | 313 | 59.75 | 2.36 | 4.28 |
| LLaVA-OneVision-1.5-4B | Charades-Ego | 628 | 58.60 | 2.33 | 11.96 |
| LLaVA-OneVision-1.5-4B | EPIC-KITCHENS | 266 | 57.89 | 2.38 | 11.04 |
| LLaVA-OneVision-1.5-4B | Ego4D | 1,351 | 62.77 | 2.56 | 10.02 |
| LLaVA-OneVision-1.5-4B | HD-EPIC | 463 | 59.83 | 2.62 | 9.03 |
| LLaVA-OneVision-1.5-4B | MECCANO | 151 | 60.93 | 2.54 | 7.61 |
| LLaVA-OneVision-1.5-4B | Self-recording | 313 | 63.26 | 2.53 | 10.10 |
| Qwen3-VL-Plus | Charades-Ego | 628 | 63.85 | 2.92 | 8.73 |
| Qwen3-VL-Plus | EPIC-KITCHENS | 266 | 65.79 | 3.11 | 6.29 |
| Qwen3-VL-Plus | Ego4D | 1,351 | 68.10 | 3.17 | 6.74 |
| Qwen3-VL-Plus | HD-EPIC | 463 | 63.71 | 2.96 | 12.20 |
| Qwen3-VL-Plus | MECCANO | 151 | 64.24 | 3.18 | 6.19 |
| Qwen3-VL-Plus | Self-recording | 313 | 69.97 | 3.14 | 5.48 |
Results are aggregated across all four task groups for each model and video source. Self-recording rows are lightly highlighted.
Self-recorded Videos
In addition to public egocentric video sources, EgoCoT-Bench includes self-recorded egocentric videos captured in diverse daily operation scenarios. This subset is used to complement public datasets with additional first-person manipulation cases and improve scenario coverage.
Before annotation, all self-recorded clips are manually checked for visual quality, hand-object visibility, privacy suitability, and whether they contain sufficient operation-centric information for reliable STSG construction and grounded QA annotation.
Quiz
Hand-Object Association
Reasoning
Benchmark Comparison
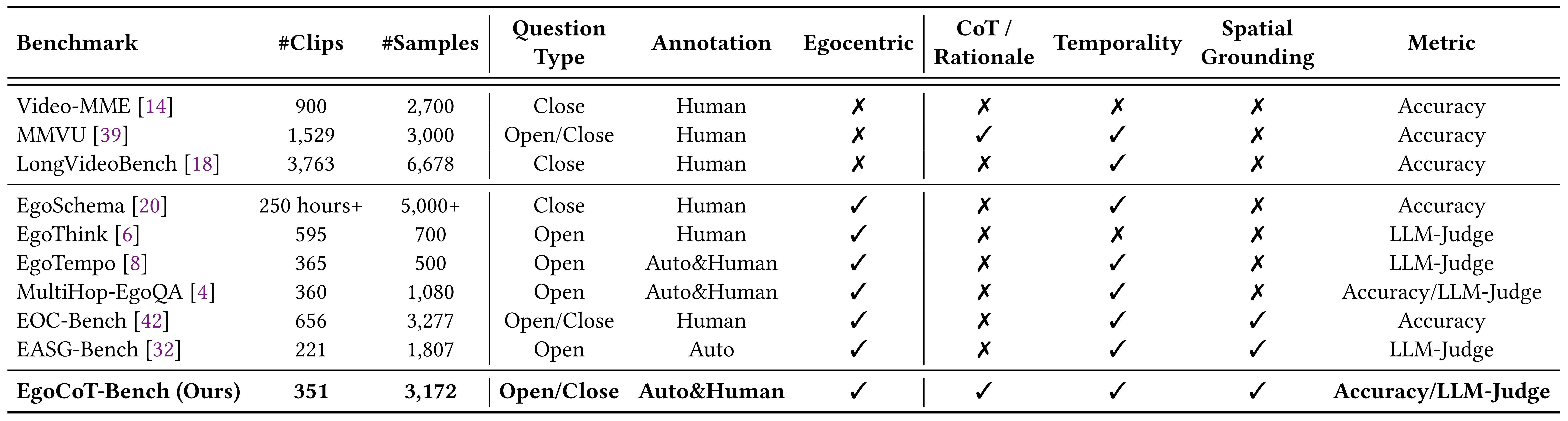
Comparison with representative video and egocentric benchmarks.
Potential Applications
EgoCoT-Bench is designed not only for benchmark evaluation, but also for diagnosing and improving grounded reasoning in first-person video understanding. With explicit answer annotations, step-by-step rationales, timestamps, bounding boxes, and interaction evidence, it can support several research directions:
Egocentric MLLM Evaluation
Evaluate whether multimodal models can correctly understand fine-grained hand-object interactions, object state changes, and short-horizon procedural reasoning in dynamic first-person videos.
Reasoning Faithfulness Diagnosis
Analyze whether answer-correct predictions are supported by temporally and spatially consistent evidence, enabling more faithful assessment beyond final answer accuracy alone.
Embodied and Assistive AI
Support research on embodied assistants, wearable agents, and human-centered systems that need to interpret ongoing manipulations, anticipate immediate next actions, and recover relevant interaction history from egocentric observations.
Training Data Curation and Error Analysis
Provide a structured testbed for identifying failure modes in grounding, retrospection, anticipation, and high-level reasoning, and for guiding future data construction, model debugging, and reasoning-oriented supervision design.
Evaluation Protocol
EgoCoT-Bench evaluates not only final answer correctness, but also the quality of the reasoning process and the consistency between them.
- Accuracy (Acc): standard answer correctness.
- Reasoning Score (R): a 0–5 score evaluating the quality of model-generated reasoning.
- Spurious Correct Rate (SCR): the percentage of answer-correct cases with inconsistent underlying reasoning.
Submission format:
{
"qid": "sample_0001",
"predicted_answer": "B",
"reasoning": "The cap is twisted before the bottle becomes open, so the twisting action causes the state change."
}Prompting Strategy and Reasoning Judge
LLM-Assisted Question Generation
Candidate question-answer pairs are generated from verified spatio-temporal scene graph (STSG) evidence rather than free-form video descriptions. For each subtask, we first traverse task-specific evidence paths to identify grounded targets, associated temporal and spatial cues, interaction relations, and local action history. We then use an LLM to render these verified structural facts into a multiple-choice question, answer options, and step-by-step rationale in a fixed JSON format.
Across subtasks, the generation prompts follow a shared principle: each sample must be directly answerable from the provided structured evidence, contain a unique and unambiguous answer, include plausible distractors, and remain traceable to explicit temporal, spatial, and interaction cues. In this way, the LLM serves as a renderer of verified structural evidence rather than a source of unconstrained content invention.
Generic generation template:
You are generating benchmark QA for egocentric video understanding.
Generate ONE multiple-choice QA pair grounded only in the provided structured egocentric evidence.
General requirements:
1. The question must be answerable using only the provided evidence.
2. The answer must be unique and unambiguous.
3. Distractors should be plausible but contradicted by the evidence.
4. The reasoning must be step-by-step and grounded in timestamps, object states,
spatial localization, and interaction relations when available.
5. Return valid JSON only.
Output format:
{
"question": "...",
"choices": {"A": "...", "B": "...", "C": "...", "D": "..."},
"answer": "A/B/C/D",
"reasoning": {"step1": "...", "step2": "...", "step3": "..."}
}LLM Judge for Reasoning Quality
We use a separate LLM judge to score model-generated reasoning on a strict 0–5 scale. The judge takes as input the question, the ground-truth answer, the annotated reference reasoning, the predicted answer, and the predicted reasoning. It evaluates the predicted reasoning in terms of logical soundness, coherence, and consistency with the ground-truth answer, and returns a JSON object containing an integer score and a brief explanation.
Empty or missing reasoning outputs are assigned a score of 0. In implementation, we use deterministic decoding with temperature set to 0.0 and require strict JSON output.
Judge prompt:
You are an expert evaluator for video question answering reasoning.
Given:
- a question,
- the ground-truth answer,
- the annotated reference reasoning,
- the model-predicted answer, and
- the model-predicted reasoning,
score the predicted reasoning on a strict 0–5 scale.
Evaluate the reasoning based on:
1. logical soundness,
2. coherence,
3. consistency with the ground-truth answer, and
4. whether the reasoning supports the predicted answer in a faithful and non-contradictory manner.
Scoring rubric:
5: logically sound, coherent, and fully supports the correct answer.
4: mostly correct and coherent, with only minor redundancy or phrasing issues.
3: largely reasonable, but contains minor mistakes or incomplete support.
2: partially relevant, but includes major logical flaws or unsupported steps.
1: mostly incoherent, weakly relevant, or poorly connected to the answer.
0: empty, irrelevant, or fundamentally incorrect.
Return strict JSON:
{
"reasoning_score": <0-5 integer>,
"analysis": "<brief explanation>"
}Benchmark Results & Judge Validation
Fine-grained benchmark results on EgoCoT-Bench. The figure summarizes subtask-level answer accuracy, group-wise reasoning quality using Reasoning Score (R) and inverted SCR. To assess the reliability of the reasoning judge, we compare LLM-based scoring against human evaluation on 2,800 randomly sampled responses. The LLM judge shows strong alignment with human assessment, achieving a high quadratic weighted kappa (QWK = 0.93), 96.7% agreement within ±1 score, and 75.3% exact agreement.
Figure 3. Fine-grained radar analysis and judge validation on EgoCoT-Bench.
Annotation Quality Assurance
To ensure correctness, egocentric relevance, and evidence-grounded reasoning quality, EgoCoT-Bench adopts a multi-stage annotation and review pipeline. This section reports quantitative statistics for candidate filtering, rejection reasons, agreement, and final quality control.
Final Quality Control Summary
Overall, EgoCoT-Bench was finalized through a structured human-in-the-loop review process that filters out ambiguous, weakly grounded, or low-quality samples. The released benchmark prioritizes answer correctness, egocentric relevance, temporal and spatial grounding fidelity, and rationale verifiability.